




Tuesday, April 2, 2013
Friday, March 8, 2013
How to Unpack Various EXE Packers using OllyDBG
How to Unpack Various EXE Packers using OllyDBG
------------------------------------------------------------------------
ASPack 2.12:
Load the exe, you will have to Shift+F9 several times. Upwards of 50
times is normal. Use Ctrl+G ESP BP technique. You'll land on a JNZ.
Trace into jump, it is pushing the oep. Trace into the ret. This
is the OEP. Dump then fix IAT. Fix dump. done.
------------------------------------------------------------------------
EZIP 1.0:
You start out on a JMP, trace into it. Ctrl+F9 (exec til ret). Scroll
down and you should find a large loop. Past that, there is a JMP EAX.
Trace into this JMP, this is the OEP. Dump, fix IAT, fix dump.
------------------------------------------------------------------------
Neolite 2.0:
Scroll down until you see JMP EAX. Put BP here. Step into
JMP. You're at the OEP. Dump and rebuild just as you would
with UPX.
------------------------------------------------------------------------
PE-PaCK 1.0:
You start on a JE with JMP right below it. Trace into the JMP. Now
you're on a PUSHAD. Use the Dump window Ctrl+G esp bp. You stop on
a JMP EAX. Trace into the JMP and you're at the OEP. Dump, rebuild
IAT, fix dump. Done.
------------------------------------------------------------------------
Petite 2.2:
Trace until you go over the PUSHAD. Click in dump window. Ctrl+G.
Type ESP. Select first two bytes in dump, set breakpoint on memory
access -> word. Back in CPU window, hit F9. Shift+F9 until you
reach POPAD/POPFW. There should be a JMP soon after the POP. Trace
into the JMP, this is the OEP. Dump process with LordPE. Open process
with imprec. Set correct OEP/IAT autotrace. Hit show invalid. Right
click and do a level 1. Fix the dump.
------------------------------------------------------------------------
UPX:
Scroll down until you reach something that looks like this:
004142C7 > 61 POPAD
004142C8 .-E9 BE6CFFFF JMP wrap.0040AF8B
004142CD 00 DB 00
004142CE 00 DB 00
Set a breakpoint on the JMP and run. Step into the JMP.
You're at the OEP. Dump with LordPE. Open process
with impRec. Set OEP with the one you just found.
Hit IAT AutoSearch. Hit Get Imports. Delete the bad
thunks. Fix the dump. Done.
------------------------------------------------------------------------
OEP Finding Techniques
#1 is just scroll down till u see
0040E23F .-E9 A479FFFF JMP upxs306.00405BE8
0040E244 5CE24000 DD upxs306.0040E25C
0040E248 60E24000 DD upxs306.0040E260
0040E24C C8734000 DD upxs306.004073C8
JMP and some shit with a bunch of 0's.
#2
F7 on the PUSHAD
goto the dump
CTRL + G
goto ESP
Set a hardware Breakpoint on WORD
that will take u straight to the jump
#3
F7 onto the PUSHAD
ctrl + T
COMMAND is one of the following "POPAD"
then CTRL + F11
Monday, February 25, 2013

Sunday, February 24, 2013
Crack Watsapp Database file encrypted with AES-128
 |
| Crack db.crypt files of Watsapp |
 |
| Watsapp database |
 |
| Decrypted Messages |
what "> /dev/null 2>&1" mean??
> /dev/null 2>&1

You need to understand the theory first and then its upto you how and where you want to apply that theory. I'll try to explain above to you.
The greater-than (>) in commands like these redirect the program’s output somewhere. In this case, something is being redirected into /dev/null, and something is being redirected into &1.
Standard in, out and error:
There are three standard sources of input and output for a program. Standard input usually comes from the keyboard if it’s an interactive program, or from another program if it’s processing the other program’s output. The program usually prints to standard output, and sometimes prints to standard error. These three file descriptors (you can think of them as “data pipes”) are often called STDIN, STDOUT, and STDERR.
Sometimes they’re not named, they’re numbered! The built-in numberings for them are 0, 1, and 2, in that order. By default, if you don’t name or number one explicitly, you’re talking about STDOUT.
That means file descriptor 0 or fd0 denotes STDIN or standard input and file descriptor 1 or fd1 denotes STDOUT or standard output and file descriptor 2 or fd2 denotes STDERR or standard error.
You can see the command above is redirecting standard output into /dev/null, which is a place you can dump anything you don’t want (often called the bit-bucket), then redirecting standard error into standard output (you have to put an & in front of the destination when you do this).
The short explanation, therefore, is “all output from this command should be shoved into a black hole.” That’s one good way to make a program be really quiet!
Friday, February 22, 2013

Thursday, February 7, 2013
What happens when you format a disk?

A new disk is like a blank sheet of paper. When it is formatted, it becomes organized into numbered blocks with an index to what is in each square, and which blocks are free to write to.
Each format type organizes the disk into a certain number of blocks of a certain size so that it can quickly read from and write to each block.
The index and the numbering system use space on the disk. So even though the empty size is 100% the formatted size is 90% or something.
When you format an old disk, you have two ways. Just erase the index, and the system thinks it can write to every block. This is a 'quick format' and leaves all the old information on the disk. A 'deep format' erases everything and starts over with no information on the disk. A disk recovery application can easily find information on a quick formatted disk.
The index and the numbering system use space on the disk. So even though the empty size is 100% the formatted size is 90% or something.
When you format an old disk, you have two ways. Just erase the index, and the system thinks it can write to every block. This is a 'quick format' and leaves all the old information on the disk. A 'deep format' erases everything and starts over with no information on the disk. A disk recovery application can easily find information on a quick formatted disk.
Tuesday, January 29, 2013
FAT FILESYSTEM
FAT
The traditional DOS filesystem types are FAT12 and FAT16. Here FAT stands for File Allocation Table: the disk is divided into clusters, the unit used by the file allocation, and the FAT describes which clusters are used by which files.Layout
First the boot sector (at relative address 0), and possibly other stuff. Together these are the Reserved Sectors. Usually the boot sector is the only reserved sector.
Then the FATs (following the reserved sectors; the number of reserved sectors is given in the boot sector, bytes 14-15; the length of a sector is found in the boot sector, bytes 11-12).
Then the Root Directory (following the FATs; the number of FATs is given in the boot sector, byte 16; each FAT has a number of sectors given in the boot sector, bytes 22-23).
Finally the Data Area (following the root directory; the number of root directory entries is given in the boot sector, bytes 17-18, and each directory entry takes 32 bytes; space is rounded up to entire sectors).
Boot sector
The first sector (512 bytes) of a FAT filesystem is the boot sector. In Unix-like terminology this would be called the superblock. It contains some general information.First an explicit example (of the boot sector of a DRDOS boot floppy).
0000000 eb 3f 90 49 42 4d 20 20 33 2e 33 00 02 01 01 00
0000020 02 e0 00 40 0b f0 09 00 12 00 02 00 00 00 00 00
0000040 00 00 00 00 00 00 00 00 00 00 70 00 ff ff 49 42
0000060 4d 42 49 4f 20 20 43 4f 4d 00 50 00 00 08 00 18
...
(See here for the complete sector. And also a MSDOS example)The 2-byte numbers are stored little endian (low order byte first).Here the FAT12 version, that is also the common part of the FAT12, FAT16 and FAT32 boot sectors. See further below.
Bytes Content
0-2 Jump to bootstrap (E.g. eb 3c 90; on i86: JMP 003E NOP.
One finds either eb xx 90, or e9 xx xx.
The position of the bootstrap varies.)
3-10 OEM name/version (E.g. "IBM 3.3", "IBM 20.0", "MSDOS5.0", "MSWIN4.0".
Various format utilities leave their own name, like "CH-FOR18".
Sometimes just garbage. Microsoft recommends "MSWIN4.1".)
/* BIOS Parameter Block starts here */
11-12 Number of bytes per sector (512)
Must be one of 512, 1024, 2048, 4096.
13 Number of sectors per cluster (1)
Must be one of 1, 2, 4, 8, 16, 32, 64, 128.
A cluster should have at most 32768 bytes. In rare cases 65536 is OK.
14-15 Number of reserved sectors (1)
FAT12 and FAT16 use 1. FAT32 uses 32.
16 Number of FAT copies (2)
17-18 Number of root directory entries (224)
0 for FAT32. 512 is recommended for FAT16.
19-20 Total number of sectors in the filesystem (2880)
(in case the partition is not FAT32 and smaller than 32 MB)
21 Media descriptor type (f0: 1.4 MB floppy, f8: hard disk; see below)
22-23 Number of sectors per FAT (9)
0 for FAT32.
24-25 Number of sectors per track (12)
26-27 Number of heads (2, for a double-sided diskette)
28-29 Number of hidden sectors (0)
Hidden sectors are sectors preceding the partition.
/* BIOS Parameter Block ends here */
30-509 Bootstrap
510-511 Signature 55 aa
The signature is found at offset 510-511. This will be the end of the sector only in case the sector size is 512.Sunday, January 27, 2013

Saturday, January 19, 2013
SIOCSIFADDR: No such device ( ERROR while getting interface flags)
SIOCSIFADDR: No such device eth0: ERROR while getting interface flags: No such device

1:edit /etc/udev/rules.d/70-persistent-net.rules or
2: delete the file(it will be recreated at every boot.)
So i would suggest you to go for option 2 and before doing so make a backup of 70-persistent-net.rules file.
Monday, January 14, 2013
NTFS Partition
When you format an NTFS volume, the format program allocates the first 16 sectors for the $Boot metadata file. First sector, in fact, is a boot sector with a "bootstrap" code and the following 15 sectors are the boot sector's IPL (initial program loader). To increase file system reliability the very last sector an NTFS partition contains a spare copy of the boot sector.
On NTFS volumes, the data fields that follow the BPB form an extended BPB. The data in these fields enables Ntldr (NT loader program) to find the master file table (MFT) during startup. On NTFS volumes, the MFT is not located in a predefined sector, as on FAT16 and FAT32 volumes. For this reason, the MFT can be moved if there is a bad sector in its normal location. However, if the data is corrupted, the MFT cannot be located, and Windows NT/2000 assumes that the volume has not been formatted. The following example illustrates the boot sector of an NTFS volume formatted while running Windows 2000. The printout is formatted in three sections: Bytes 0x00- 0x0A are the jump instruction and the OEM ID . Bytes 0x0B-0x53 are the BPB and the extended BPB. The remaining code is the bootstrap code and the end of sector marker .

Each file on an NTFS volume is represented by a record in a special file called the master file table (MFT). NTFS reserves the first 16 records of the table for special information. The first record of this table describes the master file table itself, followed by a MFT mirror record. If the first MFT record is corrupted, NTFS reads the second record to find the MFT mirror file, whose first record is identical to the first record of the MFT. The locations of the data segments for both the MFT and MFT mirror file are recorded in the boot sector.

On NTFS volumes, the data fields that follow the BPB form an extended BPB. The data in these fields enables Ntldr (NT loader program) to find the master file table (MFT) during startup. On NTFS volumes, the MFT is not located in a predefined sector, as on FAT16 and FAT32 volumes. For this reason, the MFT can be moved if there is a bad sector in its normal location. However, if the data is corrupted, the MFT cannot be located, and Windows NT/2000 assumes that the volume has not been formatted. The following example illustrates the boot sector of an NTFS volume formatted while running Windows 2000. The printout is formatted in three sections: Bytes 0x00- 0x0A are the jump instruction and the OEM ID . Bytes 0x0B-0x53 are the BPB and the extended BPB. The remaining code is the bootstrap code and the end of sector marker .

Each file on an NTFS volume is represented by a record in a special file called the master file table (MFT). NTFS reserves the first 16 records of the table for special information. The first record of this table describes the master file table itself, followed by a MFT mirror record. If the first MFT record is corrupted, NTFS reads the second record to find the MFT mirror file, whose first record is identical to the first record of the MFT. The locations of the data segments for both the MFT and MFT mirror file are recorded in the boot sector.
Byte Offset
|
Field Length
|
Field Name
|
|---|---|---|
| 0x00 |
3 bytes
|
Jump Instruction
|
| 0x03 |
LONGLONG
|
OEM ID
|
| 0x0B |
25 bytes
|
BPB
|
| 0x24 |
48 bytes
|
Extended BPB
|
| 0x54 |
426 bytes
|
Bootstrap Code
|
| 0x01FE |
WORD
|
End of Sector Marker
|
Tuesday, January 8, 2013
Function's Prologue and Epilogue
In assembly language programming, the function prologue is a few lines of code at the beginning of a function, which prepare the stack and registers for use within the function. Similarly, the function epilogue appears at the end of the function, and restores the stack and registers to the state they were in before the function was called. The prologue and epilogue are not a part of the assembly language itself; they represent a convention used by assembly language programmers, and compilers of many higher-level languages. They are fairly rigid, having the same form in each function. Sometimes, function prologue and epilogue contain also buffer overflow protection code.
A function prologue typically does the following actions if the architecture has a base pointer (also known as frame pointer) and a stack pointer (the following actions may not be applicable to those architectures that are missing a base pointer or stack pointer) :
=>Pushes the old base pointer onto the stack, such that it can be restored later (by getting the new base pointer value which is set in the next step and is always pointed to this location).
=>Assigns the value of stack pointer (which is pointed to the saved base pointer and the top of the old stack frame) into base pointer such that a new stack frame will be created on top of the old stack frame (i.e. the top of the old stack frame will become the base of the new stack frame).
=> Moves the stack pointer further by decreasing or increasing its value, depending on whether the stack grows down or up. On x86, the stack pointer is decreased to make room for variables (i.e. the function's local variables).
As an example, here′s a typical IA-32 assembly language function prologue as produced by the GCC:
pushl %ebp
movl %esp,%ebp
subl $N,%esp

Function epilogue reverses the actions of the function prologue and returns control to the calling function. It typically does the following actions (this procedure may differ from one architecture to another):
=>Replaces the stack pointer with the current base (or frame) pointer, so the stack pointer is restored to its value before the prologue
=>Pops the base pointer off the stack, so it is restored to its value before the prologue
=>Returns to the calling function, by popping the previous frame's program counter off the stack and jumping to it The given epilogue will reverse the effects of either of the above prologues (either the full one, or the one which uses enter). For example, these three steps may be accomplished in 32-bit x86 assembly language by the following instructions (using AT&T syntax):
movl %ebp,%esp
popl %ebp
ret
A function prologue typically does the following actions if the architecture has a base pointer (also known as frame pointer) and a stack pointer (the following actions may not be applicable to those architectures that are missing a base pointer or stack pointer) :
=>Pushes the old base pointer onto the stack, such that it can be restored later (by getting the new base pointer value which is set in the next step and is always pointed to this location).
=>Assigns the value of stack pointer (which is pointed to the saved base pointer and the top of the old stack frame) into base pointer such that a new stack frame will be created on top of the old stack frame (i.e. the top of the old stack frame will become the base of the new stack frame).
=> Moves the stack pointer further by decreasing or increasing its value, depending on whether the stack grows down or up. On x86, the stack pointer is decreased to make room for variables (i.e. the function's local variables).
As an example, here′s a typical IA-32 assembly language function prologue as produced by the GCC:
pushl %ebp
movl %esp,%ebp
subl $N,%esp
Function epilogue reverses the actions of the function prologue and returns control to the calling function. It typically does the following actions (this procedure may differ from one architecture to another):
=>Replaces the stack pointer with the current base (or frame) pointer, so the stack pointer is restored to its value before the prologue
=>Pops the base pointer off the stack, so it is restored to its value before the prologue
=>Returns to the calling function, by popping the previous frame's program counter off the stack and jumping to it The given epilogue will reverse the effects of either of the above prologues (either the full one, or the one which uses enter). For example, these three steps may be accomplished in 32-bit x86 assembly language by the following instructions (using AT&T syntax):
movl %ebp,%esp
popl %ebp
ret
Saturday, January 5, 2013
SWAP AND CACHE DROP PUZZLE SOLVED

In high performance computing it is common for applications to have all of the data in the physical memory to meet performance criticality. When multiple processes communicate, as we know, shared memory serves as the fastest way of IPC. Any such typical application would initialize the shared memory by loading the data from the disk into the shared memory. Now a question arises - what is the maximum data size that an application can hold in the physical memory, of course, without swapping. For the sake of discussion, if we are given a 100GB of RAM, at max, how many giga byte of physical memory (RAM) can I allocate to my data, keeping in mind that the fewer I allocate, the more boxes I would require to split the data gallery. As a test, I wrote a small app to do what I described above. As it loaded around 30 GB of data into the RAM, the kernel started using swap. After loading 40 GB, the swap usage exponentially increased and at one point in time, it stopped responding and I had to physically bounce the box (plug off and plug in again). This din't make sense to me at the beginning. At first, why would the kernel swap if there is enough RAM? I did a man proc and searched for "swap". I happened to read about /proc/sys/vm/swappiness - a parameter which defines the kernel's tendency to swap. The default value of swappiness on ubuntu8.04 is 60. As the "used" RAM size reaches 60% of the total RAM size, the kernel would being to swap. In my case, 60% of 100 GB is 60 GB. But my data size was 30 GB when the kernel started to swap. Where did the remaining 30GB go, eventually leaving my box in a non-responsive state?! Again this intrigued me to do a further search . I could not find the relation between the data size and the memory required to store it. Few more runs and a close memory monitoring showed that the kernel caches all the data (yes, almost all the data that are used very recently). Thus, if an application has loaded 2GB of data into the memory, the kernel would cache 4GB. 2 GB for the actual shared memory data and 2GB of unused cache using which the data was read/copied into the shared memory. On a typical server environment (runlevel 3), you wouldn't expect this to happen, since apart from the main apps no other applications will be running (like yum-updatesd, vlc, rhythmbox, etc). One would expect the kernel to drop the unused cache immediately. proc man page again showed one other important parameter - /proc/sys/vm/drop_caches. This entry point is helpful in instructing the kernel to drop the unused cache.
To free pagecache:
# echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
# echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes:
# echo 3 > /proc/sys/vm/drop_caches
When an application loads all the data into the memory during its initialization and then never tends to read the disk, drop_caches is a real boon. In my case above, I was able to load 90 GB of data into the shared memory and share it with the other processes. The technique was to clear the cache frequently as the application initialized.
while :; do echo 3 > /proc/sys/vm/drop_caches sleep 30 done
As a thumb rule, swappiness must be set to 0 (echo 0 > /proc/sys/vm/swappiness or via sysctl.conf) before the application starts and the drop_caches must be set to 3 periodically to avoid any kind of swaps and performance degradations. Once the app has been initialized and all the 90GB has been loaded into the memory, the while loop to drop the unused cache is not needed and it can be terminated safely. But the moment you do a huge file read, don't forget to run the script in the background, of course, as root. The need to drop_caches entirely depends on your application. Setting swappiness to 0 is ideal in my opinion for all the server environments where you have to run only specific application on systems.
Friday, January 4, 2013
Block Addressing In Hard Drives
A hard disk drive (HDD) is a data storage device used for storing and retrieving digital information using rapidly rotating discs (platters) coated with magnetic material. An HDD retains its data even when powered off. Data is read in a random-access manner, meaning individual blocks of data can be stored or retrieved in any order rather than just sequentially. An HDD consists of one or more rigid ("hard") rapidly rotating discs (platters) with magnetic heads arranged on a moving actuator arm to read and write data to the surfaces.
Following two schemes are used to address the location on hard drive which store some useful information
1:)Logical block addressing (LBA) is a common scheme used for specifying the location of blocks of data stored on computer storage devices, generally secondary storage systems such as hard disks.
LBA is a particularly simple linear addressing scheme; blocks are located by an integer index, with the first block being LBA 0, the second LBA 1, and so on.
| LBA Value | CHS Tuple |
|---|---|
| 0 | 0, 0, 1 |
| 1 | 0, 0, 2 |
| 2 | 0, 0, 3 |
| 62 | 0, 0, 63 |
| 945 | 0, 15, 1 |
| 1007 | 0, 15, 63 |
| 1008 | 1, 0, 1 |
| 1070 | 1, 0, 63 |
| 1071 | 1, 1, 1 |
| 1133 | 1, 1, 63 |
| 1134 | 1, 2, 1 |
| 2015 | 1, 15, 63 |
| 2016 | 2, 0, 1 |
| 16,127 | 15, 15, 63 |
| 16,128 | 16, 0, 1 |
| 32,255 | 31, 15, 63 |
| 32,256 | 32, 0, 1 |
| 16,450,559 | 16319, 15, 63 |
| 16,514,063 | 16382, 15, 63 |
CHS (cylinder/head/sector) tuples can be mapped to LBA address with the following formula:
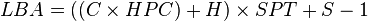
where,
C, H and S are the cylinder number, the head number, and the sector number
LBA is the logical block address
HPC is the maximum number of heads per cylinder (reported by disk drive, typically 16 for 28-bit LBA)
SPT is the maximum number of sectors per track (reported by disk drive, typically 63 for 28-bit LBA)
LBA addresses can be mapped to CHS tuples with the following formula:
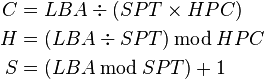
2:)Cylinder-head-sector, also known as CHS, was an early method for giving addresses to each physical block of data on a hard disk drive. In the case of floppy drives, for which the same exact diskette medium can be truly low-level formatted to different capacities, this is still true.
Though CHS values no longer have a direct physical relationship to the data stored on disks, virtual CHS values (which can be translated by disk electronics or software) are still being used by many utility programs.

Wednesday, January 2, 2013
BACKUP PARTITION TABLE
In computer hardware, GUID Partition Table (GPT) is a standard for the layout of the partition table on a physical hard disk. Although it forms a part of the Extensible Firmware Interface (EFI) standard (Intel's proposed replacement for the PC BIOS), it is also used on some BIOS systems because of the limitations of MBR partition tables, which use 32 bits for storing logical block addresses and size information. For disks with 512-byte sectors, the MBR partition table entries allow up to a maximum of 2.20 TB (2.20 × 1012 bytes) or 2 TiB−512 bytes (2,199,023,255,040 bytes or 4,294,967,295 (232−1) sectors × 512 (29) bytes per sector).[1] GPT allocates 64 bits for logical block addresses and therefore allows a maximum disk and partition size of 264−1 sectors. For disks with 512-byte sectors, that would be 9.4 ZB (9.4 × 1021 bytes)[1][2] or 8 ZiB−512 bytes (9,444,732,965,739,290,426,880 bytes or 18,446,744,073,709,551,615 (264−1) sectors × 512 (29) bytes per sector).
Using Following two ways you can store Partition table.

1:)dd the old good command which now backup partition tables. Backing up partition is nothing but actually backing up MBR (master boot record). The command is as follows for backing up MBR stored on /dev/sdX or /dev/hdX depending upon whether you are using scsi or ide :
# dd if=/dev/sdX of=/tmp/sda-mbr.bin bs=512 count=1
Replace X with actual device name such as /dev/sda.
Now to restore partition table to disk, all you need to do is use dd command:
# dd if= sda-mbr.bin of=/dev/sdX bs=1 count=64 skip=446 seek=446
446 bytes of Bootstrap code, then 4 partition entries x 16 bytes = 64 bytes, then 2 bytes of signature (a 16 bit number = 0101010110101010).
2:)We can get a quick look on all the existing partitions on all the available hard drives with fdisk using the -l switch without any other parameter
mango@pineapple:~$ sudo fdisk -l
[sudo] password for mango:
Disk /dev/sda: 16.1 GB, 16106127360 bytes
255 heads, 63 sectors/track, 1958 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk identifier: 0x0000a1e3
Device Boot Start End Blocks Id System
/dev/sda1 * 1 1870 15020743+ 83 Linux
/dev/sda2 1871 1958 706860 5 Extended
/dev/sda5 1871 1958 706828+ 82 Linux swap / Solaris
mango@pineapple:~$ sudo sfdisk -d /dev/sda
# partition table of /dev/sda
unit: sectors
/dev/sda1 : start= 63, size= 30041487, Id=83, bootable
/dev/sda2 : start= 30041550, size= 1413720, Id= 5
/dev/sda3 : start= 0, size= 0, Id= 0
/dev/sda4 : start= 0, size= 0, Id= 0
/dev/sda5 : start= 30041613, size= 1413657, Id=82
Using sfdisk with the -d option we can get a dump of the current partition table in a regular file, and if needed we can restore it from that file:
sfdisk -d /dev/sda > sdaTable
and to restore the partition table:
sfdisk /dev/sda <>sdaTable
Subscribe to:
Comments (Atom)